Super Fast Circular Ring Buffer Using Virtual Memory trick
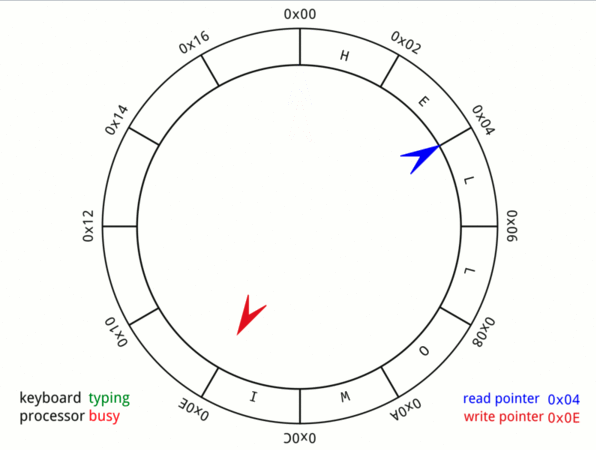
A circular buffer is a data structure that uses a single, fixed-size buffer as if it were connected end-to-end. The useful property of circular buffer is that it doesn’t need to have its elements shuffled around when an element is produced/ consumed.
Circular queues are commonly used in producer-consumer applications, logger buffers etc.
Circular buffers are usually implemented using fixed sized arrays. A simple implementation of circular buffer might look like this:
Elements are added to the buffer using tail index sequentially. When last element of array is reached, the index is wrapped around using modulo operator.
If the elements are trivially copyable, then memcpy may be used instead. Using memcpy (instead of loop) avoids expensive modulo operator, and looping for copy. Removing modulo operator from for loop also makes it easy for the compiler to vectorize the copy operation.
The first memcpy handles data copy till buffer end and second one handles data copy from buffer beginning (wrap-around). This means we have effectively two copy operations, which may be vectorized individually.
Page Table Hacking
We can further optimize the enqueue operation to use only one memcpy instead of two. We can exploit hardware to handle the wrap around more efficiently for us. This can be achieved by allocating two contiguous regions of virtual memory side-by-side, allowing us to overrun the end of the array in virtual address space. This can be visualized using the following example:
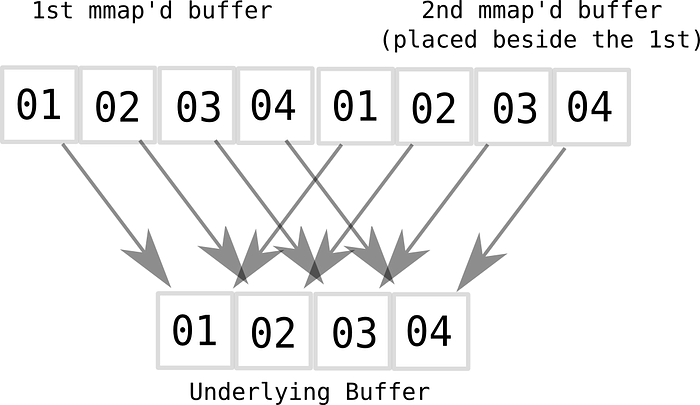
This can be achieved using mmap. From man page of mmap:
mmap() creates a new mapping in the virtual address space of the calling process.
Now leveraging this memory mapping, we can write our enqueue function using just a single memcpy, thus vectorizing the whole operation at once.
That’s it. Any wrap around is automatically handled directly by hardware during memory translations.
How does this work?
Here we are mapping 2 blocks of virtual memory to 1 block of physical memory. This is called aliasing.
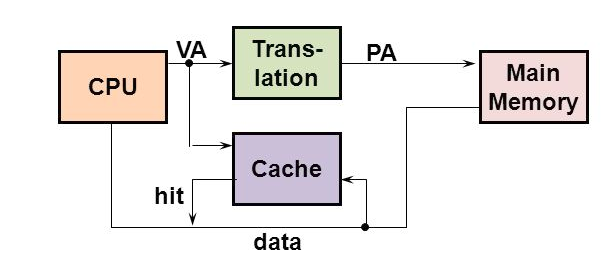
Typically processors have VIPT (virtually indexed and physically tagged) write-back caches. Virtual indexing allows searching in cache even before TLB translation has completed, i.e., TLB translation and cache lookup can be executed in parallel. But using this can cause aliasing problem as different virtual address (which are mapped to same physical address) might be indexed to different cache locations. To handle this, hardware manufacturers ensure that all index bits comes from page offset part of virtual address only. Since page offset is same for virtual and physical address, this ensures that any virtual address which maps to same physical address, index to same cache slot. After indexing, physical tag is used to retrieve the cache line, which will ofcourse be same as physical address are same.
Conclusion
Exploiting virtual memory trick for circular buffer enqueue operation is handled efficiently in hardware and has significantly better performance, at the cost of doubling the page table entries (which is mostly ok!).